 SWE-bench
SWE-bench
Overview
SWE-bench Lite provides a smaller, carefully selected subset of 300 tasks from the full benchmark, designed to:
- Reduce evaluation costs while maintaining benchmark quality
- Enable faster iteration cycles for model development
- Provide a more accessible entry point for research groups
The 300 tasks were selected to preserve the distribution and difficulty spectrum of the original benchmark while focusing on more self-contained, functional bug fixes.
While the full SWE-bench test split comprises 2,294 issue-commit pairs across 12 Python repositories, SWE-bench Lite covers 11 of the original 12 repositories with a similar diversity and distribution. We also provide 23 development instances that can be useful for active development on the SWE-bench task.
We recommend future systems evaluating on SWE-bench to report numbers on SWE-bench Lite in lieu of the full SWE-bench set when compute efficiency is a concern.
Selection Criteria
SWE-bench Lite instances were selected using the following criteria:
- Removed instances with images, external hyperlinks, references to specific commit SHAs and references to other pull requests or issues
- Removed instances with fewer than 40 words in the problem statement
- Removed instances that edit more than 1 file
- Removed instances where the gold patch has more than 3 edit hunks
- Removed instances that create or remove files
- Removed instances that contain tests with error message checks
- Finally, sampled 300 test instances and 23 development instances from the remaining candidates
The source code for how SWE-bench Lite was created is available in SWE-bench/swebench/collect/make_lite.
Repository Distribution
SWE-bench Lite distribution across repositories. Compare to the full SWE-bench in Figure 3 of the SWE-bench paper.
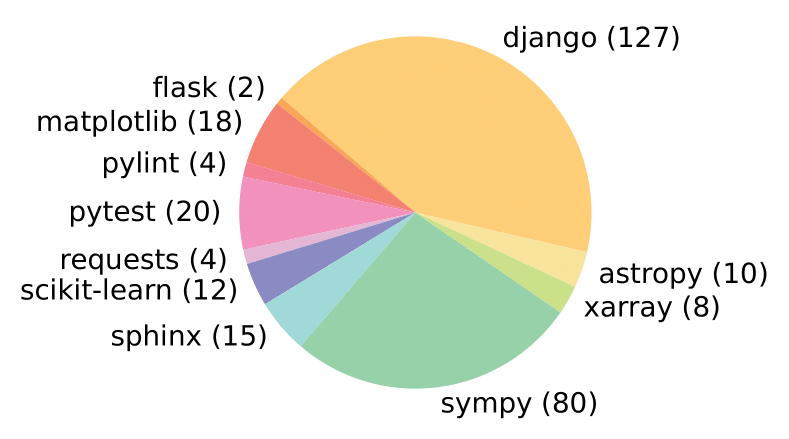
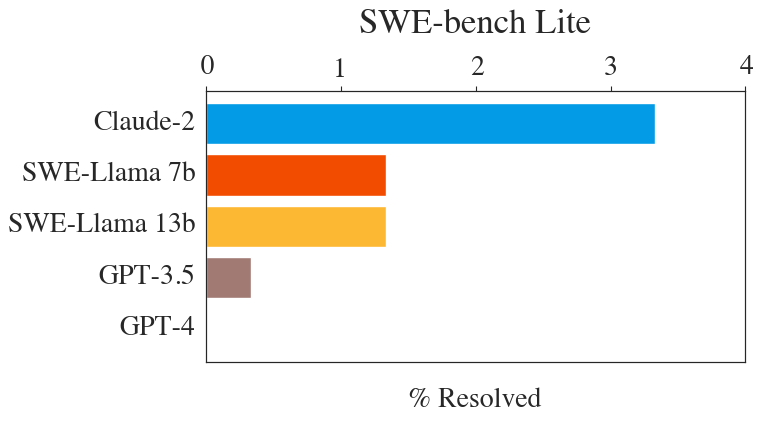
Baseline Performance
SWE-bench Lite performance for our baselines. Compare to the full SWE-bench baseline performance in Table 5 of the SWE-bench paper.
Resources
SWE-bench Lite datasets:
Citation
If you use SWE-bench in your research, please cite our paper:
@inproceedings{
jimenez2024swebench,
title={{SWE}-bench: Can Language Models Resolve Real-world Github Issues?},
author={Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=VTF8yNQM66}
}
Jimenez, C. E., Wettig, A., Yao, S., Yang, J., Pei, K., Jain, S., Press, O., & Narasimhan, K. (2024). SWE-bench: Can Language Models Resolve Real-world Github Issues? arXiv preprint arXiv:2310.06770.
Jimenez, Carlos E., et al. "SWE-bench: Can Language Models Resolve Real-world Github Issues?" arXiv preprint arXiv:2310.06770 (2023).